

Conceituação do Ceph parameters e Placement Groups
Jornada Proxmox Parte 4
Versão 1
Emissão: 16 de setembro de 2022
Validade: Indeterminada
Tema: Ceph Placement Groups & Parameters
Objetivo
Neste artigo iremos passar algumas informações conceituais para equipe técnica sobre algumas configurações do Ceph que poderão, quando integrado ao Proxmox, ser ajustados conforme necessidade do administrador de sistema. Nosso foco é a configuração do Cluster Proxmox, desse modo, apesar do conceito se aplicar a uma instalação e configuração de Ceph padrão, nossa abordagem se dará em vista do nosso laboratório e com objetivo único de garantir a alta disponibilidade do nosso cluster PVE e o live migration das nossas máquinas virtuais e containers. Lembrando então que estamos usando três servidores Proxmox no nosso laboratório. Os laboratórios foram apresentados nas partes 1, 2 e 3 dessa jornada. Desse modo, esse artigo pretende resolver a seguinte questão: quais são os principais conceitos, configurações e parâmetros de um cluster de storage Ceph? A configuração de um Cluster Storage é então necessária para garantia da alta disponibilidade de um ambiente produtivo com Proxmox.
Nosso material tem como base o treinamento oficial de Proxmox da RunbookBR que não é comercializado. Nesse sentido, o material oficial é restrito a aplicação para nossas equipes internas.

Pré-Requisitos
- Para melhor entendimento deste artigo, recomendo a leitura da parte 1 dessa jornada, bem como as partes 2 e 3. Apesar de não ser exatamente uma premissa, a leitura dos artigos da Jornada Proxmox na ordem em que foi elaborado ajudará na contextualização do exposto neste artigo.
- Ainda assim, recomendo também que você possua conhecimento básico em redes de computadores e familiaridade com termologias relacionadas a tecnologia da informação.
Laboratório do Cluster Proxmox com Ceph
Durante a Jornada Proxmox da RunbookBR apresentamos primeiramente nosso ambiente de laboratório montado com: 2 servidores Intel Xeon E31270, all flash, oito discos SSD, duas interfaces de rede Gigabit Ethernet e 16 GB RAM cada.
Do mesmo modo montamos um desktop Intel Core i5 2400 com um disco mecânico e 16 GB RAM e uma interface de rede. No entanto, esse desktop não fará parte do cluster de discos Ceph, assim, será usado na topologia apenas como monitor do Cluster Ceph.
Parâmetros do Ceph Pool
- Name: Nome que identificará a sua partição lógica no cluster PVE
- Size: Também chamado de Resilience, basicamente é o número de réplicas que cada objeto receberá dentro do seu cluster Ceph.
- PG Autoscale Mode: Permite que o sistema se ajuste automaticamente (no caso de On) ou recomende mudanças (no caso de Warn) nos placement groups baseados no seu uso. Falaremos mais sobre Placement Groups na sequência.
- Add as Storage: Adiciona o novo Pool à configuração de armazenamento do cluster. Em outras palavras, disponibiliza a partição lógica para utilização no nosso ambiente de virtualização.
- Min Size: Aqui definimos o número mínimo de réplicas dos nossos objetos para “permissão” de I/O. Imagine que você tenha três discos físicos compondo seu cluster. Se você tem um bit de paridade em cada um, em tese você continuará com todos os seus dados íntegros mesmo que você perca dois discos, certo? Agora… você vai querer utilizar o seu sistema nessa condição? Basicamente é com isso que você precisa se preocupar quando define essa opção. Por padrão, nesse cenário simplista que expus, você precisaria de pelo menos dois discos íntegros para permitir a leitura e escrita dos dados no seu disco lógico e nesse contexto seu Min Size seria 2.
- of PGs: Placement Groups fala muito de como funciona o algoritmo do Ceph. Não é nada tão simples que eu vá conseguir esclarecer totalmente, mas vou me esforçar para resumir no capítulo a seguir.
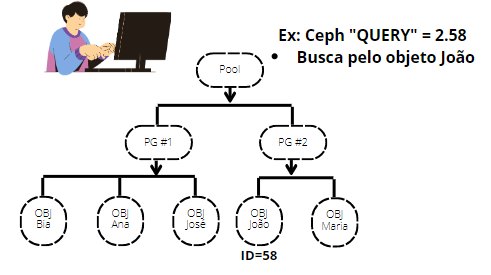
Um pouco mais sobre Placement Groups
Visão Geral do Ceph Placement Group
Pense no PG como um agrupamento de dados que usam um algoritmo inteligente o suficiente para garantir disponibilidade, eficiência e performance no processamento de entrada e saída de dados. Se você já ouviu falar em indexação em banco de dados, podemos dizer que ele segue aproximadamente a mesma ideia, onde ao invés de percorrer uma consulta por toda estrutura de dados, o algoritmo do sistema busca um “atalho” por indexações lógicas que direcionam a consulta para um caminho mais específico. Esse assunto é muito extenso e complexo e tentarei trazer em artigos futuros, mas creio que já tenha dado uma clareada. De modo geral, use a facilidade do auto PG, mas não deixe de entender mais profundamente esse tema para potencializar sua performance em um ambiente de grande porte.
Calculo Base do PG
Uma conta padrão para definição manual do PG em um ambiente até 50 OSD é a seguinte:
Até 5 OSD = 128
Maior que 5, até 10 OSD = 512
Maior que 10, até 50 OSD = 1024
Se você tiver mais de 50 OSDs, recomendamos aproximadamente 50 a 100 grupos de posicionamento por OSD para equilibrar o uso de recursos, a durabilidade dos dados e a distribuição. Se você tiver menos de 50 OSDs, é melhor escolher entre a pré-seleção citada anteriormente. Para um único conjunto de objetos, você pode usar a seguinte fórmula para obter uma linha de base
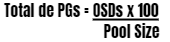
Em que o tamanho do pool é o número de réplicas para pools replicados ou a soma K+M para pools codificados para eliminação (conforme retornado por ceph osd erasure-code-profile get ).
O resultado deve sempre ser arredondado para a potência de dois mais próxima.
Apenas uma potência de dois equilibrará uniformemente o número de objetos entre os grupos de posicionamento. Outros valores resultarão em uma distribuição desigual de dados em seus OSDs. Devemos usar de maneira limitada e passar gradualmente de uma potência de dois para outra.
Como exemplo, para um cluster com 200 OSDs e um tamanho de pool de 3 réplicas, você estimaria seu número de PGs da seguinte maneira

Equilíbrio dos PGs no Ceph
Ao usar vários pools de dados para armazenar objetos, você precisa equilibrar o número de grupos de posicionamento por pool com o número de grupos de posicionamento por OSD para chegar a um número total razoável de grupos de posicionamento que forneça variação razoavelmente baixa por OSD sem sobrecarregar os recursos do sistema ou tornar o processo de peering muito lento.
Por exemplo, um cluster de 10 pools com 512 grupos de posicionamento em dez OSDs tem um total de 5.120 grupos de posicionamento distribuídos em dez OSDs, ou seja, 512 grupos de posicionamento por OSD. Esse cenário não usa muitos recursos. No entanto, se você cria 1.000 pools com 512 grupos de posicionamento cada, os OSDs lidarão com aproximadamente 50.000 grupos de posicionamento cada e isso exigiria muito mais recursos e tempo para emparelhamento.
Referencia completa do Ceph
A referência completa do assunto pode ser consultada na documentação oficial do ceph.
Conclusão
Por fim, vimos no artigo de hoje uma parte importante da conceituação de um ambiente de Storage com Ceph, uma solução de Object Store que se integra ao Proxmox dando ao administrador de infraestrutura de TI maior flexibilidade, dinamismo e segurança para focar seus esforços na garantia da alta disponibilidade (H.A) do seu ambiente de servidores. Esse conceito será de suma importância para o próximo artigo dessa jornada, quando iremos, enfim, configurar o serviço do Ceph integrado ao Proxmox.
Acompanhe os próximos artigos dessa jornada, onde mostrarei todas as etapas que precisam ser realizadas para que nossa proposta de chegar a um ambiente com 99,99% de disponibilidade seja alcançado.
Na parte 5 dessa jornada iremos iniciar a instalação e configuração do nosso Cluster Ceph.
Nosso canal no YouTube terá apresentações em vídeos explicativos sobre os temas abordados nesta jornada, servindo como material adicional de consulta.
Até a próxima, te espero no próximo artigo.


